Stel je voor dat je de toekomst kunt voorspellen. Niet op een magische manier, maar met behulp van data en slimme algoritmes. Dat is precies wat regressie in machine learning mogelijk maakt. Het is een krachtige techniek die ons helpt verbanden te ontdekken en voorspellingen te doen over numerieke waarden, zoals de prijs van een huis, de verkoopcijfers van een product of de temperatuur van morgen.
Wat betekent regressie nu precies in de context van machine learning? Simpel gezegd, regressie is een type supervised learning algoritme dat wordt gebruikt om de relatie tussen een afhankelijke variabele (wat we willen voorspellen) en een of meer onafhankelijke variabelen (de factoren die de voorspelling beïnvloeden) te modelleren. Het doel is om een functie te vinden die deze relatie het beste beschrijft, zodat we accurate voorspellingen kunnen doen voor nieuwe, ongeziene data.
Regressieanalyse is een essentieel onderdeel van machine learning en wordt in talloze toepassingen gebruikt, van financiële voorspellingen tot medische diagnoses. Het begrijpen van de betekenis en werking van regressie is daarom cruciaal voor iedereen die zich bezighoudt met data-analyse en machine learning.
De oorsprong van regressieanalyse ligt in de statistiek, met de pionierswerk van Francis Galton en Karl Pearson in de 19e eeuw. Zij bestudeerden de relatie tussen de lengte van ouders en hun kinderen en ontwikkelden de eerste regressiemodellen. Sindsdien heeft de techniek zich enorm ontwikkeld en is het een onmisbaar instrument geworden in machine learning.
Een belangrijk probleem bij regressie is overfitting. Dit gebeurt wanneer het model te complex wordt en de ruis in de trainingsdata leert in plaats van de onderliggende relatie. Dit leidt tot slechte prestaties op nieuwe data. Technieken zoals regularisatie en cross-validation worden gebruikt om overfitting te voorkomen.
Een eenvoudig voorbeeld van regressie is het voorspellen van de prijs van een huis op basis van de grootte. De grootte is de onafhankelijke variabele en de prijs is de afhankelijke variabele. Een lineair regressiemodel kan een rechte lijn vinden die de relatie tussen deze twee variabelen het beste beschrijft.
Voordelen van regressie in machine learning zijn: accurate voorspellingen van continue waarden, inzicht in de relatie tussen variabelen en de mogelijkheid om verschillende soorten data te analyseren.
Voor- en Nadelen van Regressie
| Voordelen | Nadelen |
|---|---|
| Accurate voorspellingen | Gevoelig voor outliers |
| Inzicht in relaties tussen variabelen | Kan overfitten |
| Flexibel en toepasbaar op diverse datasets | Vereist zorgvuldige data preprocessing |
Vijf beste praktijken voor regressie zijn: data cleaning, feature engineering, modelselectie, hyperparameter tuning en evaluatie.
Vijf concrete voorbeelden van regressie zijn: voorspellen van huisprijzen, voorspellen van verkoopcijfers, voorspellen van de temperatuur, voorspellen van de levensverwachting en voorspellen van de aandelenkoers.
FAQ:
1. Wat is regressie? Regressie is een techniek om de relatie tussen variabelen te modelleren.
2. Wat zijn de soorten regressie? Lineaire regressie, polynomiale regressie, etc.
3. Hoe kies ik het juiste regressiemodel? Afhankelijk van de data en het probleem.
4. Wat is overfitting? Wanneer het model te complex is en de ruis leert.
5. Hoe voorkom ik overfitting? Door regularisatie en cross-validation.
6. Wat zijn evaluatiemetrieken voor regressie? MSE, RMSE, R-squared.
7. Wat is feature engineering? Het transformeren van variabelen om de modelprestaties te verbeteren.
8. Waar kan ik meer leren over regressie? Online cursussen, boeken en documentatie.
Tips: Gebruik visualisaties om de data te begrijpen en experimenteer met verschillende modellen.
Regressie in machine learning is een krachtige tool die ons in staat stelt om voorspellingen te doen en inzichten te verkrijgen uit data. Het begrijpen van de betekenis, toepassingen en beperkingen van regressie is essentieel voor iedereen die data-gedreven beslissingen wil nemen. Door de juiste technieken en best practices toe te passen, kunnen we regressiemodellen bouwen die accurate en betrouwbare voorspellingen leveren. De continue ontwikkeling van nieuwe regressiemethoden en de toenemende beschikbaarheid van data zorgen ervoor dat regressie een steeds belangrijkere rol zal spelen in de toekomst van machine learning en data science. Begin vandaag nog met het verkennen van de mogelijkheden van regressie en ontdek de waardevolle inzichten die het kan bieden.

Top Machine Learning Algorithms for Regression - Trees By Bike

What Is Regression in Machine Learning - Trees By Bike

Excel linear regression intercept - Trees By Bike

Linear Regression Basics for Absolute Beginners - Trees By Bike

what is the meaning of regression in ml - Trees By Bike

The sweet hidden meaning behind the Bridgerton carriage scene song - Trees By Bike

What is the meaning of label in matplotlibpyplotplotwhy we use label - Trees By Bike
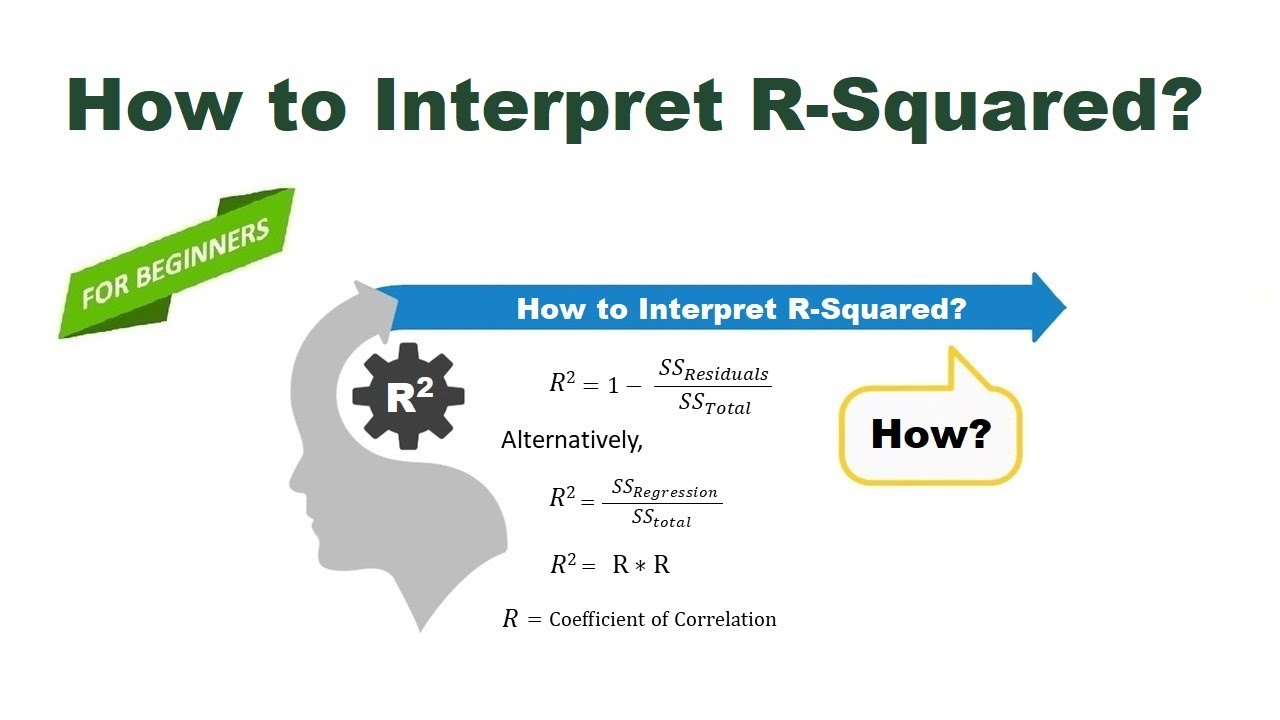
what is the meaning of regression in ml - Trees By Bike
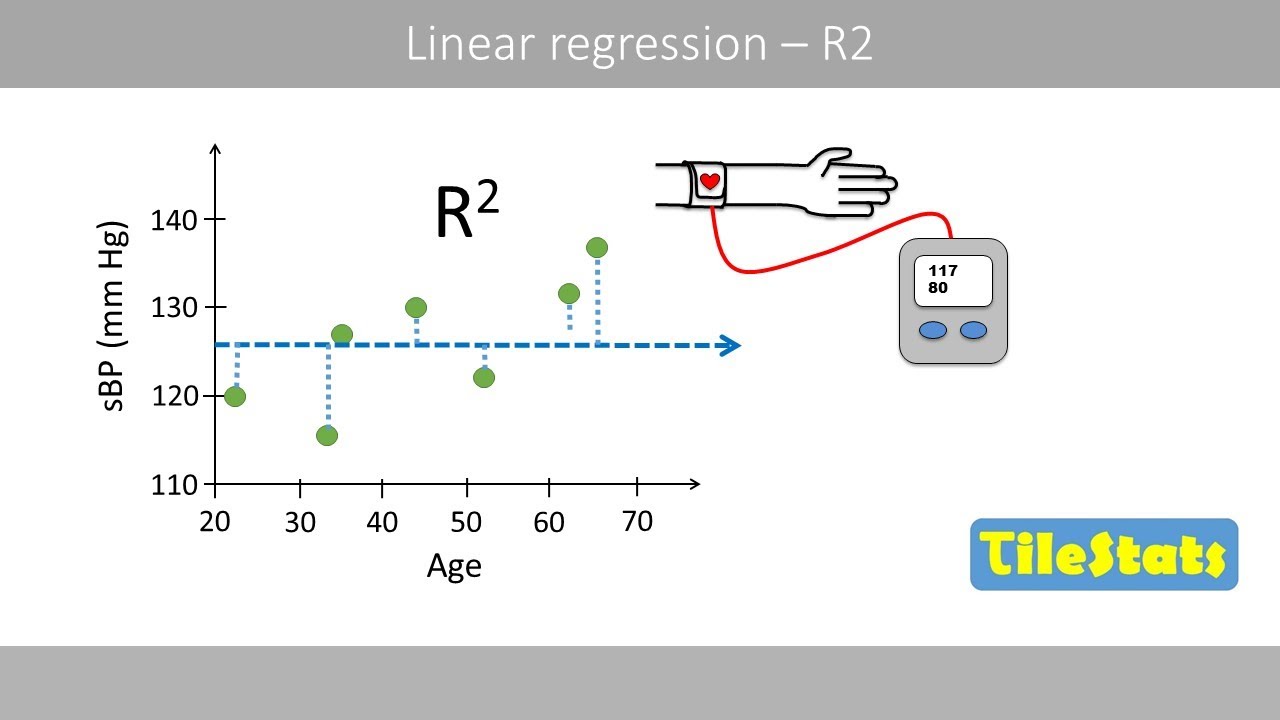
what is the meaning of regression in ml - Trees By Bike

what is the meaning of regression in ml - Trees By Bike

Multiple Linear Regression Everything You Need to Know About - Trees By Bike
Predictive Regression Modeling Vector Icon Design Stock Vector Image - Trees By Bike

what is the meaning of regression in ml - Trees By Bike

Simple linear regression equation example - Trees By Bike

5 Machine Learning Models Explained in 5 Minutes - Trees By Bike