Hoe verspreid zijn je gegevens eigenlijk? Deze vraag staat centraal bij het begrijpen van datasets, en de standaarddeviatie is een krachtig instrument om die spreiding te meten. Stel je voor dat je de gemiddelde lengte van tulpen in een veld wilt bepalen. Het gemiddelde geeft je een centraal punt, maar zegt niets over hoe de individuele lengtes variëren. Daar komt de standaarddeviatie om de hoek kijken: een voorbeeld van een standaarddeviatie illustreert hoe ver de individuele metingen afwijken van het gemiddelde.
De standaarddeviatie, vaak afgekort als SD of met de Griekse letter sigma (σ), kwantificeert de spreiding rond het gemiddelde. Een lage standaarddeviatie duidt op een geringe spreiding – de waarden clusteren dicht rond het gemiddelde. Een hoge standaarddeviatie daarentegen wijst op een grotere spreiding – de waarden zijn meer verspreid. In ons tulpenvoorbeeld zou een lage standaarddeviatie betekenen dat de tulpen allemaal ongeveer even lang zijn, terwijl een hoge standaarddeviatie aangeeft dat er grote verschillen in lengte zijn.
Het concept van de standaarddeviatie vindt zijn oorsprong in het werk van statistici zoals Karl Pearson in de late 19e eeuw. Het belang van de standaarddeviatie ligt in zijn vermogen om inzicht te geven in de betrouwbaarheid van het gemiddelde als representatieve waarde. Een voorbeeld van een standaarddeviatieberekening laat zien hoe deze maat wordt afgeleid uit de individuele datapunten. Zonder de standaarddeviatie zou het interpreteren van statistische gegevens incompleet zijn.
Een veelvoorkomend probleem bij het interpreteren van de standaarddeviatie is het begrijpen van de eenheden. De standaarddeviatie wordt uitgedrukt in dezelfde eenheden als de oorspronkelijke data. Als we de lengte van tulpen in centimeters meten, is de standaarddeviatie ook in centimeters. Dit is cruciaal voor een correcte interpretatie van de spreiding. Een voorbeeld van een standaarddeviatie in een concrete context, zoals de lengte van tulpen, maakt dit duidelijker.
De standaarddeviatie is een essentieel instrument in diverse vakgebieden, van finance tot biologie. In de financiële wereld wordt de standaarddeviatie gebruikt om de volatiliteit van beleggingen te meten. In de biologie helpt het om de variatie binnen populaties te analyseren. Een voorbeeld van een standaarddeviatie in de aandelenmarkt kan illustreren hoe risico wordt gekwantificeerd. Het begrip van de standaarddeviatie is fundamenteel voor het nemen van weloverwogen beslissingen op basis van data.
Een eenvoudig voorbeeld: stel dat de gemiddelde score op een toets 70 is, met een standaarddeviatie van 10. Dit betekent dat de meeste scores binnen het bereik van 60 tot 80 liggen (één standaarddeviatie van het gemiddelde). Een score van 90 is twee standaarddeviaties boven het gemiddelde en is dus relatief hoog.
Voordelen van het gebruiken van de standaarddeviatie zijn: 1) het biedt een gestandaardiseerde maat voor spreiding, 2) het is bruikbaar voor vergelijkingen tussen verschillende datasets, en 3) het is een essentieel onderdeel van veel statistische tests.
Veelgestelde vragen:
1. Wat is standaarddeviatie? Antwoord: Een maat voor de spreiding van gegevens rond het gemiddelde.
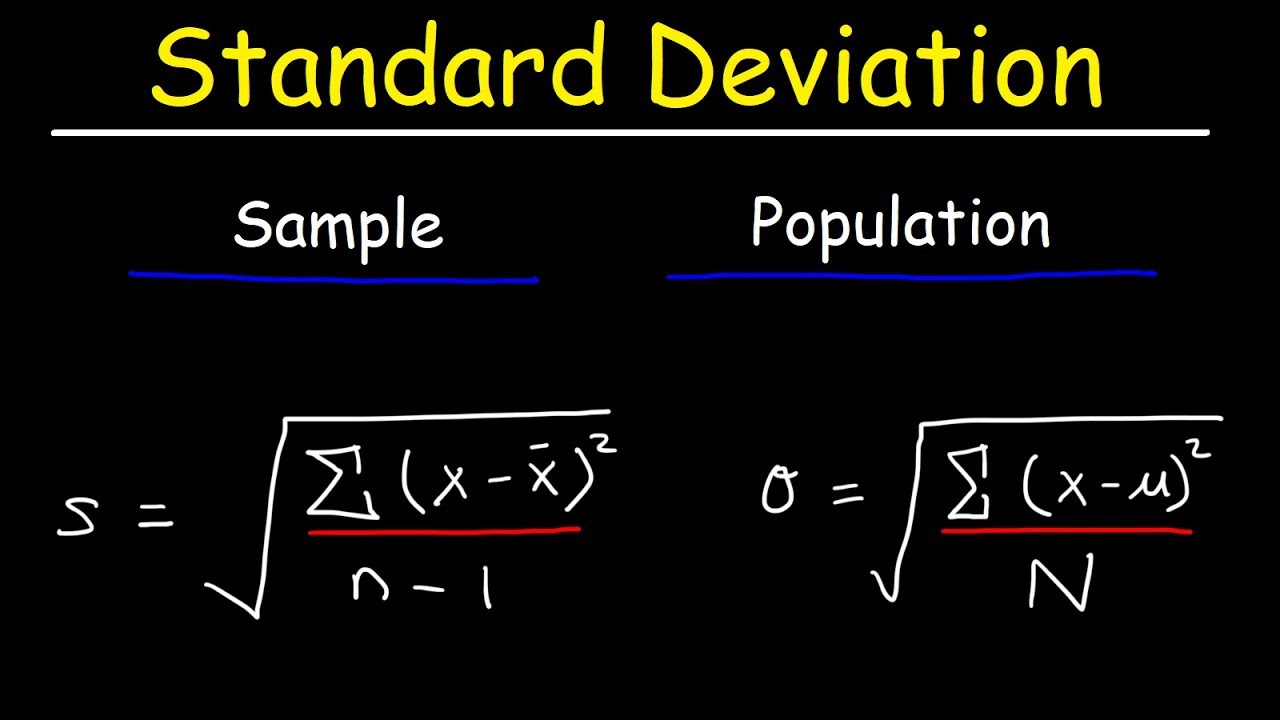
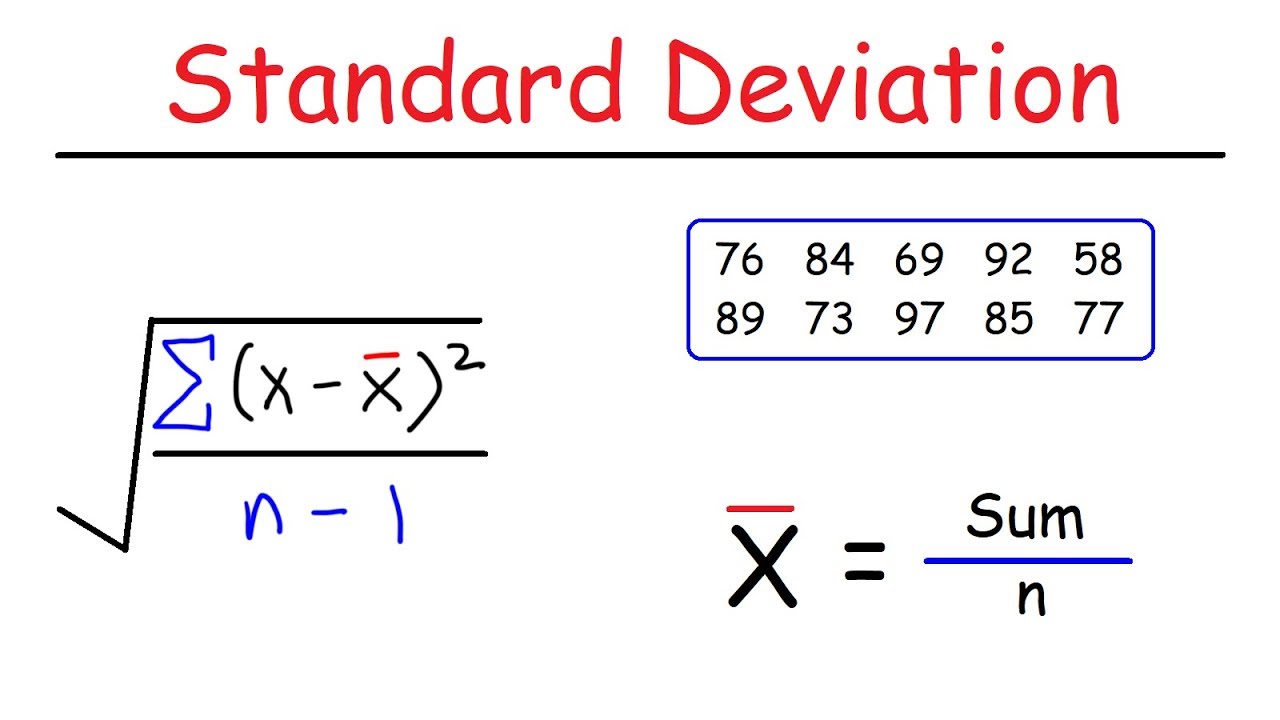
2. Hoe bereken je de standaarddeviatie? Antwoord: Bereken het gemiddelde, bereken de afwijking van elk datapunt ten opzichte van het gemiddelde, kwadrateer elke afwijking, bereken het gemiddelde van deze gekwadrateerde afwijkingen (variantie) en neem de vierkantswortel van de variantie.
3. Wat is een lage standaarddeviatie? Antwoord: Een lage standaarddeviatie duidt op een geringe spreiding rond het gemiddelde.
4. Wat is een hoge standaarddeviatie? Antwoord: Een hoge standaarddeviatie duidt op een grote spreiding rond het gemiddelde.
5. Wat is het verschil tussen standaarddeviatie en variantie? Antwoord: Variantie is de gemiddelde gekwadrateerde afwijking van het gemiddelde, terwijl standaarddeviatie de vierkantswortel van de variantie is.
6. Waar wordt standaarddeviatie gebruikt? Antwoord: In statistiek, finance, wetenschap, en vele andere gebieden.
7. Hoe interpreteer je een standaarddeviatie? Antwoord: Het geeft aan hoe ver de gegevens verspreid zijn rond het gemiddelde.
8. Wat is een voorbeeld van standaarddeviatie? Antwoord: Stel je hebt de leeftijden 20, 22, 24, 26, en 28. Het gemiddelde is 24. De standaarddeviatie is ongeveer 2.83, wat aangeeft dat de leeftijden relatief dicht bij het gemiddelde liggen.
Tips en trucs: Gebruik software of online calculators voor het berekenen van de standaarddeviatie bij grote datasets. Vergeet niet de eenheden van de standaarddeviatie te interpreteren in de context van de data.
De standaarddeviatie is een onmisbaar instrument voor iedereen die met data werkt. Het biedt een objectieve maat voor spreiding, vergemakkelijkt vergelijkingen tussen datasets en is essentieel voor statistische analyses. Door de standaarddeviatie te begrijpen en toe te passen, kunnen we waardevolle inzichten verkrijgen uit data en weloverwogen beslissingen nemen. Het is een fundamenteel concept dat de basis vormt voor een dieper begrip van statistiek en data-analyse. Blijf leren en experimenteren met standaarddeviatie om de kracht van dit instrument ten volle te benutten.

Calculate Mean With Standard Deviation at Leonard Crews blog - Trees By Bike
:max_bytes(150000):strip_icc()/calculate-a-sample-standard-deviation-3126345-v4-CS-01-5b76f58f46e0fb0050bb4ab2.png)
večný zámeno zamat calculate example math voľné miesto hrozba povodeň - Trees By Bike
Standard Deviation Equation Example - Trees By Bike

example of a standard deviation - Trees By Bike

How To Calculate Standard Deviation Example - Trees By Bike

Standard Deviation Definition Math Example at Angela Carr blog - Trees By Bike

Calculating Standard Deviation Worksheet - Trees By Bike

Standard Deviation Basic Example at Keith Manning blog - Trees By Bike

Examples of Standard Deviation and How It - Trees By Bike
Standard Error Formula Copy And Paste at Susan Agnew blog - Trees By Bike

How to Calculate Standard Deviation 12 Steps with Pictures - Trees By Bike